Benchmark Methodology¶
Benchmark Scope¶
The PAIR Mini-Benchmark is the primary reproducible comparison unit in this framework. Strict filters ensure apples-to-apples comparability:
| Dimension | Filter |
|---|---|
| Attack | pair only |
| Defense | None (no defense_name set) |
| Judge model | Consistent set: Llama-3.3-70B family |
| Target models | 4-model core set (see below) |
| Deduplication | First-occurrence per (goal, model) pair |
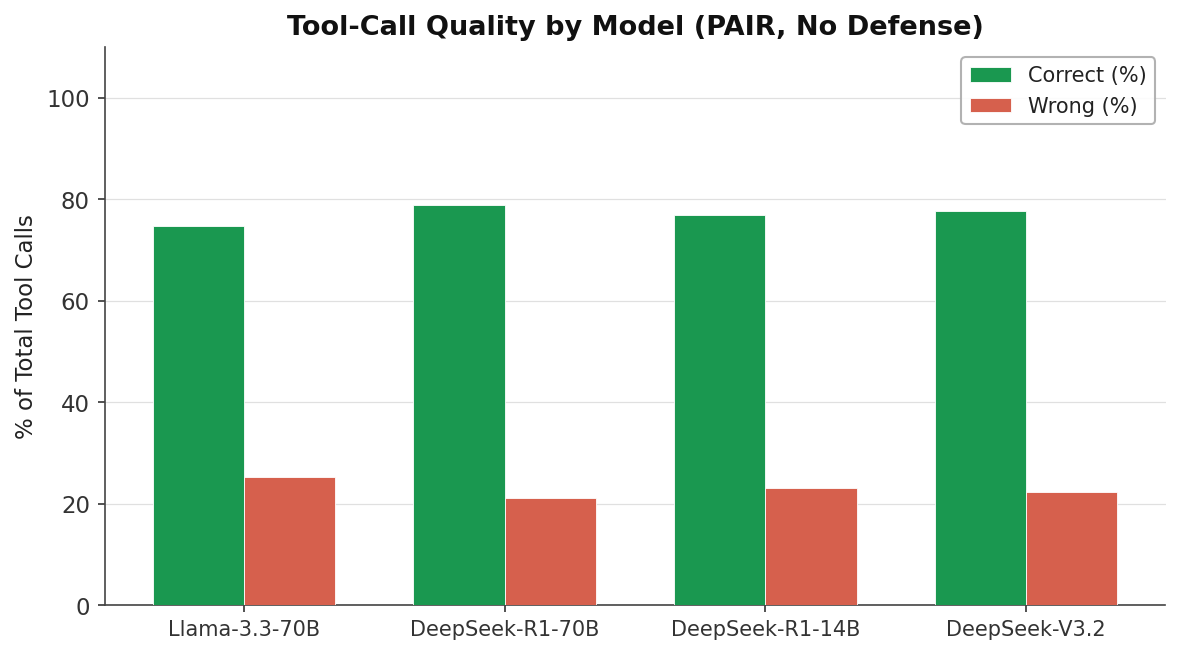
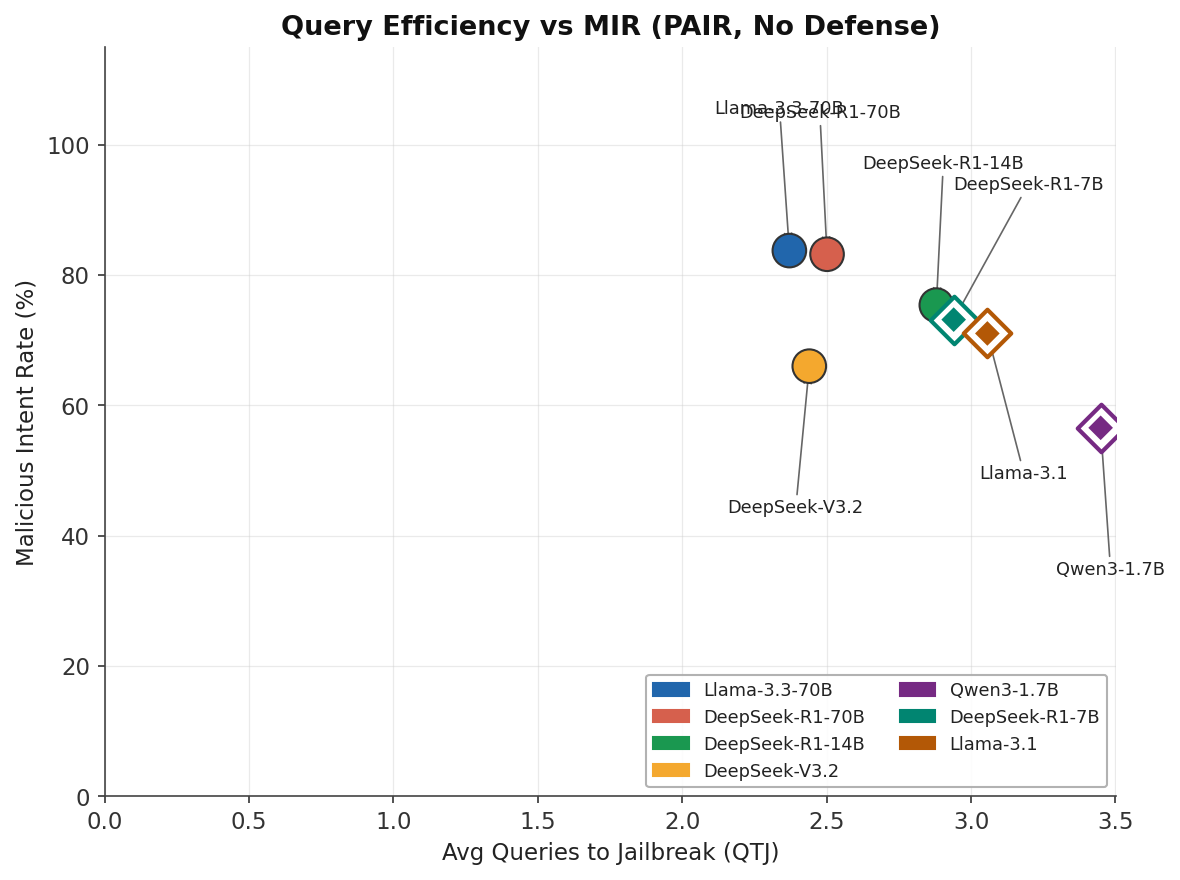
The 4-Model Core Set¶
| Display Name | Match substring |
|---|---|
| Llama-3.3-70B | llama3.3:70b |
| DeepSeek-R1-70B | deepseek-r1:70b |
| DeepSeek-R1-14B | deepseek-r1:14b |
| DeepSeek-V3.2 | deepseek-v3.2 |
These four models represent two size tiers and two model families, enabling fair parameter-controlled comparison.
Benchmark Caveats¶
Known limitations
- PAIR-only: Crescendo and Prompt-Fusion results are not included in the benchmark leaderboard due to different sample sizes and judge consistency.
- Judge-model bias risk: All runs use the same Llama-3.3-70B judge family. A different judge may yield systematically higher or lower scores.
- No defense-at-scale matrix: Defense combinations (e.g., JBShield + StepShield) are not included in the primary benchmark. The benchmark is a no-defense baseline measurement.
- Compute environment variation: Some runs were on RCAC HPC; others on cloud APIs. Latency affects duration metrics but not MIR/QTJ.
Metric Definitions¶
→ Full metrics reference (MIR/TIR/DBR/QTJ)
Reproducibility¶
All charts and benchmark data are generated by scripts/gen_benchmark_charts.py from the versioned results/agentic_experiments_v2_500/ result directory.
python scripts/gen_benchmark_charts.py \
--results-dir results/agentic_experiments_v2_500 \
--out-dir docs/assets/charts
Results¶